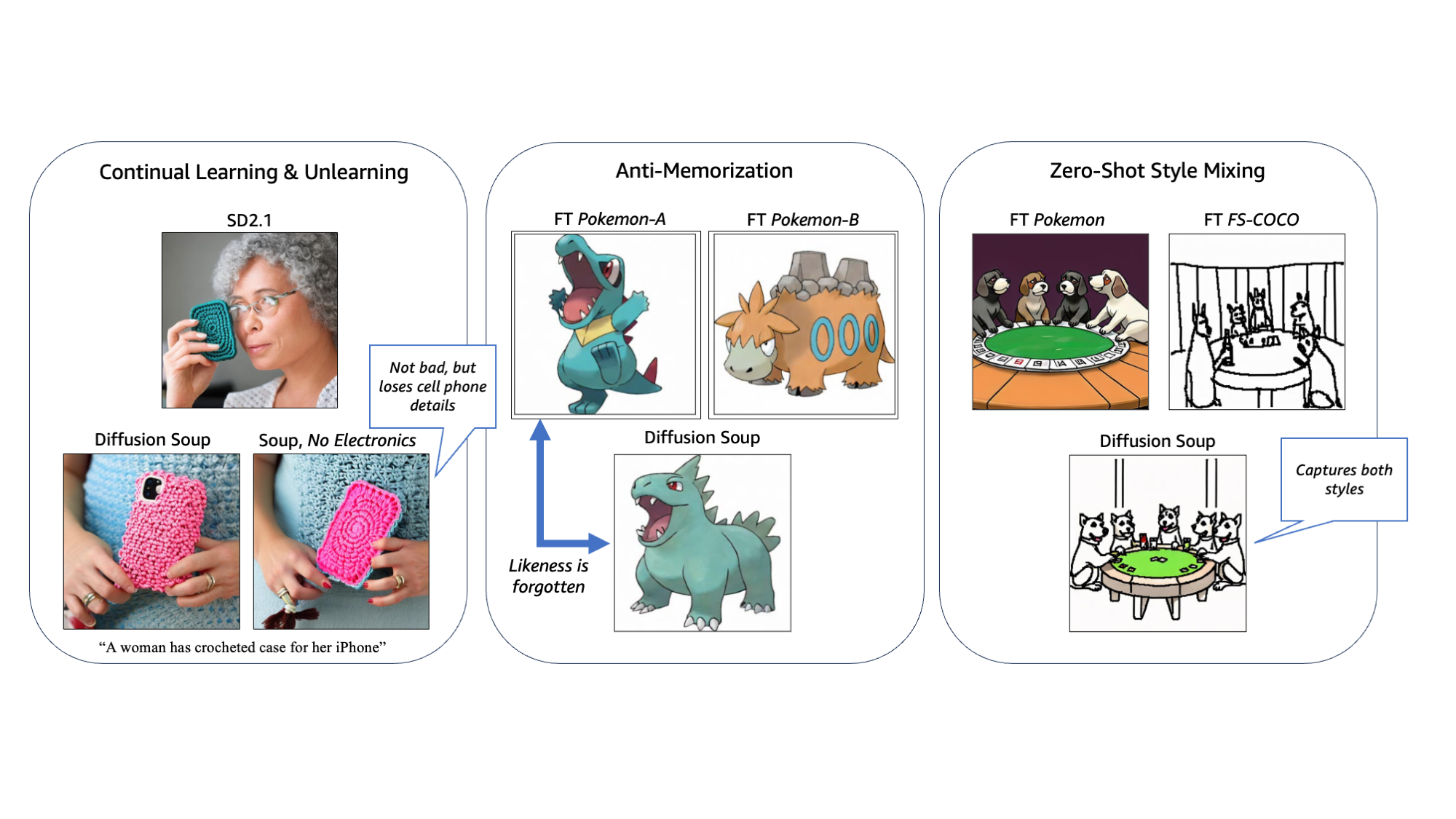
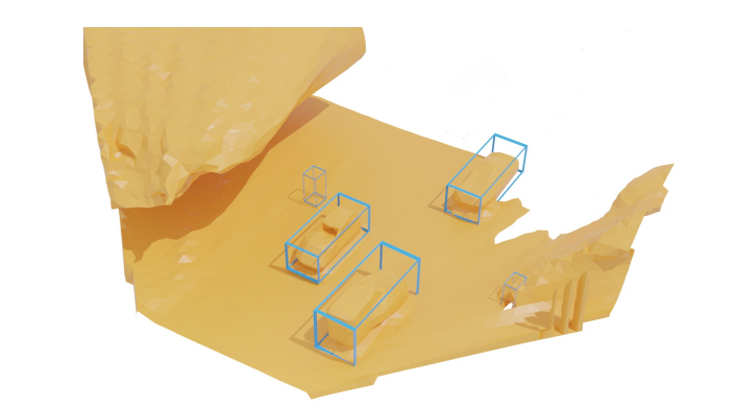
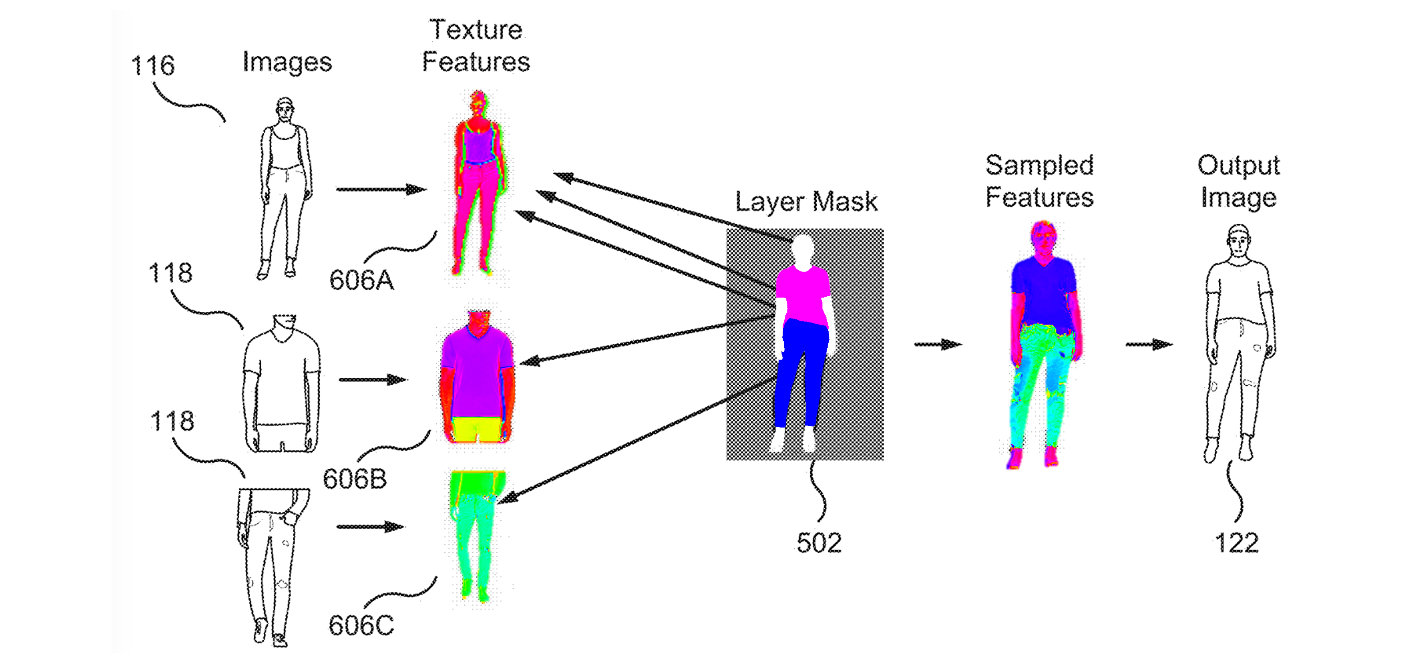
I am a Research Scientist at Luma AI, where I work on unified understanding and generation models.
Previously, I was a Senior Applied Scientist at Amazon AGI, where I worked on the Amazon Nova family of generative models and Amazon Titan Image Generator.
I received my PhD in Computer Vision & Deep Learning from the University of Cambridge where I focused on 3D reconstruction of human and animal categories.
Outside the lab, I am a pianist, singer, theatre-goer and somewhat reluctant runner.
Position
Research Scientist, Luma AI
Location
San Francisco, California, United States